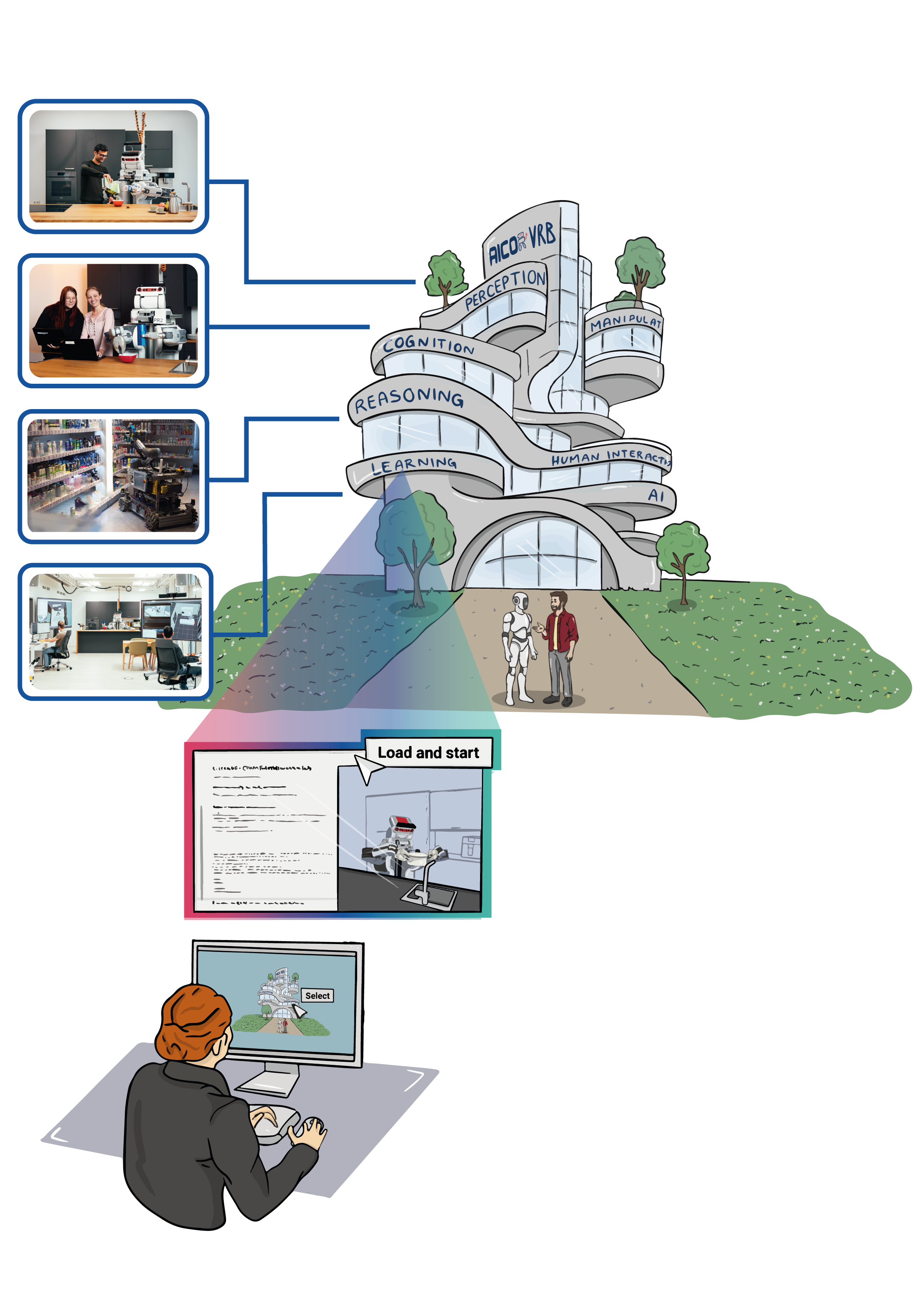
For Entering Chapter one click here: Chapter 1!
Welcome to the First Chapter of Our Hands-On Course!
In dynamic robotic environments, scene graphs represent complex spatial relationships. They map “who is where” and “what connects to what” in complex, dynamic spaces. With scene graphs, robots can navigate, adapt, and interact intelligently, as you’ll see in the video of our lab simulation. By linking the scene graph to a semantic knowledge base, robots gain contextual awareness, allowing them to reason about the environment, anticipate changes, and make informed decisions.
In this chapter, you’ll learn how to create a scene graph using URDF (Unified Robot Description Format). URDF is essential because it helps define the structure, shape, and physical properties of objects, allowing robots to interact with them accurately in a simulated environment. After creating the scene graph you will extend it with semantic information, creating a semantic digital twin.
Part 1: Introduction to Scene Graphs in URDF
Goal
By the end of this session, you will have worked with a simple URDF model that includes essential objects like a fridge, a table, and other items, and visualized this setup in RVIZ.
Theoretical Background
What is URDF?
URDF stands for Unified Robot Description Format. It was originally designed for describing robots, specifically their physical structure and properties. A robot is an electromechanical device composed of multiple bodies (also called links) connected by joints. Each link represents a physical part of the robot, and joints define how these parts move relative to each other.
URDF is not limited to describing robots. In this course, we use it to define and simulate an entire environment as a scene graph, modeling furniture, objects, and other items the robot will interact with. It creates a virtual representation of an environment by defining the structure, shape, and physical properties of objects, which is crucial for realistic simulations.
Links and Joints in URDF

- Visual: defines how the link appears in the simulation.
- Collision: defines the simplified shape used to detect collisions, kept simpler than the visual to reduce computational load.
- Inertial: defines how the link behaves under physical forces, important for physics-based simulations like Gazebo.

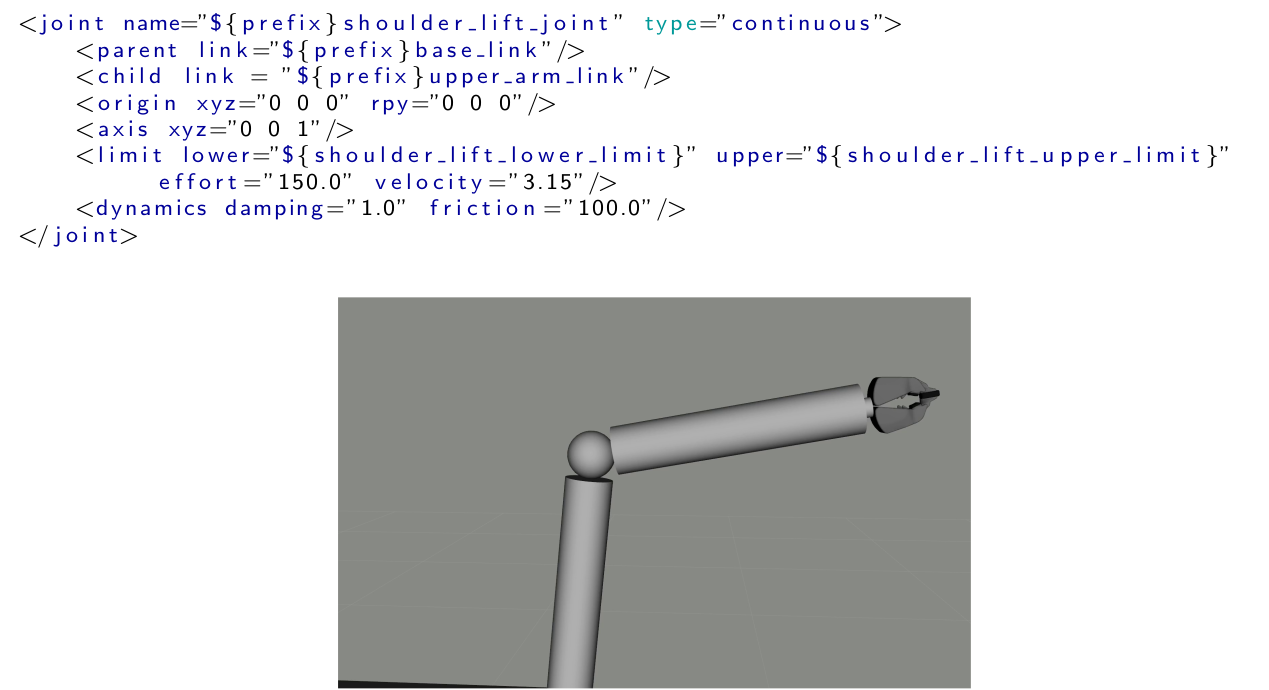
A joint in URDF defines how two links are connected and how they move relative to each other. Each joint requires specific parameters to describe its properties, such as the type of joint (e.g., revolute or prismatic), the axis of movement, and the parent and child links it connects. Additionally, limits can be defined for revolute and prismatic joints to specify the range of motion. The following image will illustrate an example of how a joint is defined in URDF for a robot arm.
Hands-On Exercise 1
- Load a basic URDF file structure and visualize it.
- Add and modify objects in the scene graph: integrate models for the fridge, table, and other essential items.
By the end of this session, you will have a working URDF environment and understand how to create and visualize a scene graph in URDF. Throughout the exercises, code examples demonstrate how to define links, joints, and meshes.
To run the interactive Hands-On Tutorial, click here: URDF Hands-On Lab
Further Reading
- An in-depth URDF tutorial can be found here.
- Challenge: Try adding a new object, like a cup, to your environment and adjust its position to fit the scene.
Part 2: Scene Graphs and Knowledge Representation: Semantic Digital Twins
Goal
By the end of this session, you will understand how to extend the scene graph concept to represent knowledge in a semantic digital twin, allowing for richer interaction between the robot and its environment.
Theoretical Background
What is Knowledge Representation for Robotics and Why is it Important?
Knowledge representation in robotics is a way to organize information so that robots can reason about the world around them. It involves encoding the relationships between objects, actions, and properties, allowing robots to interpret and interact with their environment intelligently. Knowledge representation is important because it enables robots to make informed decisions, understand complex instructions, and adapt to dynamic environments, which is especially crucial for autonomous and cognitive robotic tasks. The diagram below shows how a knowledge processing system could look like. The scene graph is connected to the knowledge graph, which is then used by reasoner to answer questions like “Which objects do I need for breakfast?” or “Which objects contain something to drink?”

Knowledge graphs and ontologies are a fundamental tool in knowledge representation, particularly useful for organizing and connecting information about objects, actions, and their relationships in a meaningful way. Ontologies define the core concepts, relationships, and rules in a domain—like what “Grasping” means and the requirements for it. Knowledge graphs, built on these ontologies, hold specific instances and connections, such as a particular milk carton on a table. This structure allows robots to answer targeted questions, like “What objects do I need for breakfast?”. By combining both, robots gain a flexible framework for reasoning, integrating broad concepts with real-time, specific data.
Knowledge representation in robotics organizes information so that robots can reason about the world. It encodes relationships between objects, actions, and properties, allowing robots to interpret and interact with their environment. This enables robots to make informed decisions, understand complex instructions, and adapt to dynamic environments. The diagram below shows how a knowledge processing system could look: the scene graph connects to the knowledge graph, which a reasoner then uses to answer questions like “Which objects do I need for breakfast?” or “Which objects contain something to drink?”

What is a Semantic Digital Twin and Why is it Important?
A semantic digital twin is an enriched digital representation of a real-world entity that includes not just physical details, but also semantic information about the relationships, roles, and functions of objects. In robotics, a semantic digital twin allows a robot to understand both the physical properties of objects (e.g., shape and material) and their intended use or role in tasks. This semantic layer is crucial for enabling robots to perform complex tasks involving interactions with multiple objects and adapting to changing environments. By incorporating semantic knowledge, robots can reason more effectively about how to complete a task, making them more capable of handling unpredictable scenarios.

What is USD and How Do We Use it to Create a Knowledge Graph?
Universal Scene Description (USD) is a powerful format for representing complex scenes and environments in 3D. In robotics, USD can be used to create a unified scene graph that integrates data from different sources like URDF, MJCF, and SDF. This standardization into USD makes it easier to enrich the scene with semantic information. Using USD, we can create a semantic map by linking scene graph nodes to concepts in a robot ontology, such as SOMA or KnowRob, effectively transforming a scene graph into a knowledge graph.

The USD file format stores 3D scenes as hierarchical scene graphs (or stages). A stage is composed of different components such as prims, layers, metadata and schemas. So called composition arcs further allow for efficient data sharing and reuse between different parts of a scene. USD also includes a powerful animation system that can be used to store and manage complex animations within a scene. In USD, data is arranged hierarchically into namespaces of prims (primitives). Each prim can hold child prims, as well as attributes and relationships, referred to as properties. Attributes have typed values that can change over time, while relationships are pointers to other objects in the hierarchy, with USD automatically remapping the targets when namespaces change due to referencing. In addition, both prims and properties can have non-time-varying metadata. All of these elements, including prims and their contents, are stored in a layer, which is a scene description container for USD. This hierarchical structure allows for easy organization of the scene, and enables transformations and properties to be inherited from parent prims to their children. This example shows how a cardboard box with two flaps can be represented using a hierarchy of prims in USD.
def Xform "world" () {
def Xform "box" (
prepend apiSchemas = ["PhysicsMassAPI", ...]
) {
matrix4d xformOp:transform = ( ... )
token[] xformOpOrder = ["xformOp:transform"]
point3f physics:centerOfMass = ( ... )
float physics:mass = 2.79
def Cube "geom_1" ( ... ) { ... }
def PhysicsRevoluteJoint "box_flap_1_joint" {
rel physics:body0 = </world/box>
rel physics:body1 = </world/box_flap_1>
}
def PhysicsRevoluteJoint "box_flap_2_joint" {
rel physics:body0 = </world/box>
rel physics:body1 = </world/box_flap_2>
}
}
def Xform "box_flap_1" ( ... ) { ... }
def Xform "box_flap_2" ( ... ) { ... }
}
- Challenge: Try creating an OWL from your own environment and find interesting queries!
Further Reading
- An in-depth tutorial for OWL and RDF can be found here.
- Publication for the USD scene translation into knowledge graphs:
- Publication for the SOMA ontology:
- Knowledge base, as a reasoning engine for Knowledge Graphs: